[OS-반효경] File Systems Implementation
Allocation of File Data in Disk, Free-Space Management
저번 포스팅에는 File System을 알아 보았습니다. 이번 포스팅에서는 파일 시스템에 대한 구현이 어떻게 되었는지를 알아 보겠습니다.
Allocation of File Data in Disk
파일이 디스크에 할당되는 방법에는 Contiguous Allocation(연속 할당), Linked Allocation, Indexed Allocation가 있습니다.
Contiguous Allocation
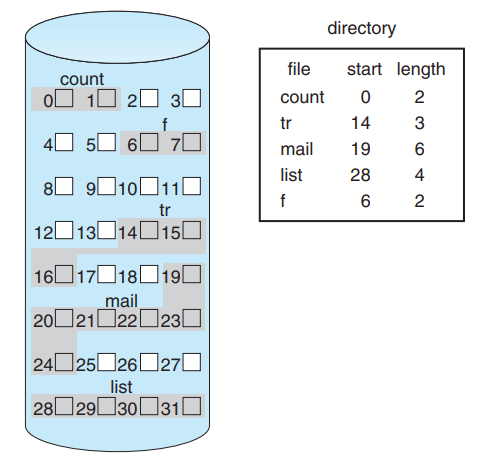
Contiguous Allocation(연속 할당)은 디스크에 한 파일의 데이터를 연속적으로 할당하는 방법입니다.
한 번의 seek/rotation으로 많은 바이트를 전송할 수 있어 빠른 입출력이 가능하고, 임의 접근이 가능합니다.
하지만 외부 단편화 문제가 있고, 파일 크기가 늘어나면 확장 유연성이 떨어지는 문제가 있습니다.
Linked Allocation
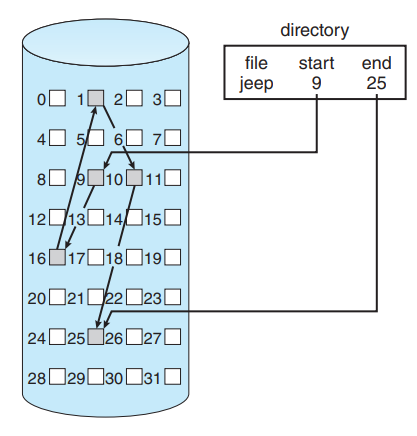
Linked Allocation은 파일의 각 데이터 블록이 다음 블록의 포인터를 저장해 연결 리스트처럼 이어지도록 디스크 블록을 할당하는 방식입니다.
공간이 충분히 비어있는 디스크에 할당하기 때문에, 외부 단편화는 발생하지 않습니다.
하지만 임의 접근이 불가능하고, seek()에 많은 시간이 걸릴 수 있습니다.
또한 한 sector가 고장나 pointer가 유실되면, 많은 정보를 잃어버릴 수 있는 Reliability 문제가 있습니다.
Indexed Allocation
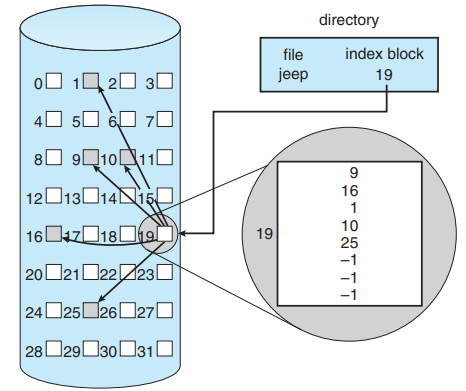
Indexed Allocation은 파일마다 인덱스 블록을 두고, 그 안에 파일이 사용하는 모든 데이터 블록의 주소를 모아 저장해 접근하는 할당 방식입니다.
데이터 블록이 연속일 필요가 없어 외부 단편화가 없고, 직접 접근이 가능합니다. 하지만 인덱스 블록/포인터 저장 공간이 추가로 필요해 작은 파일에서는 공간이 낭비되고, 파일이 매우 크면 인덱스 블록 1개에 모든 주소를 담기 어려운 문제가 있습니다. 이때 인덱스를 확장하는 방식으로 해결하는데, 대표적으로 Linked Index와 Multi-Level Index가 있습니다.
파일 시스템 구조
앞에서 살펴본 할당 방식이 실제 운영체제의 파일 시스템에서는 어떤 메타 데이터 구조로 구현되는지 확인해 보겠습니다.
UNIX 파일 시스템 구조
UNIX 계열 파일 시스템은 inode 기반의 Indexed Allocation으로 구현되어 있습니다.
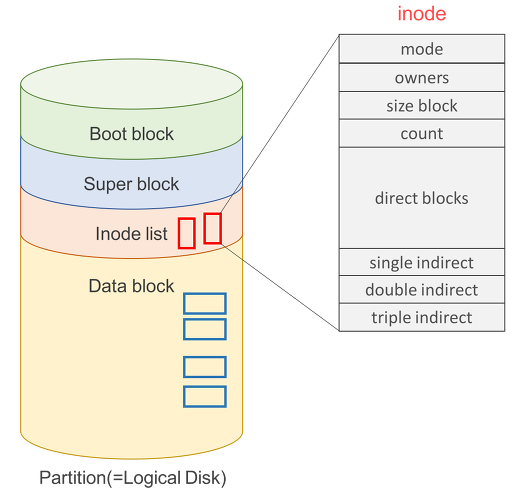
UNIX 계열 파일 시스템은 Boot Block, Super Block, Inode List, Data Block로 구성되어 있습니다.
각 블럭에 대해 간단하게 정리하겠습니다.
Boot Block: 부팅에 필요한 정보Super Block: 파일 시스템에 대한 총체적인 정보Inode List: 파일 이름에 대한 정보를 제외한 모든 메타 데이터 정보Data Block: 파일의 실제 내용
MS DOS 파일 시스템 구조(FAT File System)
MS DOS 계열 파일 시스템은 FAT(File-Allocation Table) 파일 시스템이라고도 하며 Indexed Allocation로 구현되어 있습니다.
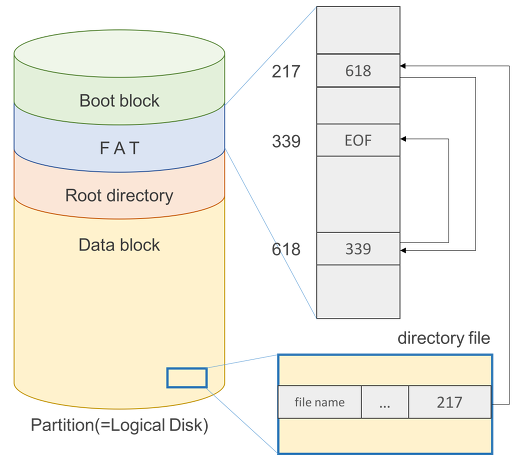
FAT 파일 시스템은 Boot Block, FAT, Root directory, Data Block로 구성되어 있습니다.
Boot Block: 부팅에 필요한 정보FAT: 메타 데이터 일부(위치 정보)Root directory: 루트 디렉터리의 엔트리들이 저장되는 영역 → 디렉터리 정보Data Block: 파일의 실제 내용
Free-Space Management
파일 시스템은 파일을 생성하거나 크기가 증가할 때 새로운 블록을 할당해야 하므로, 디스크에서 사용 가능한 블록을 추적하고 빠르게 찾는 방법이 필요합니다. 이를 위해 파일 시스템은 빈 공간 정보를 별도의 메타데이터로 관리하며, 대표적으로 Bit map/Bit Vector, Linked List, Grouping, Counting 방식이 사용됩니다.
Bit map/Bit Vector
Bit map/Bit Vector 알고리즘은 디스크의 각 블록이 비어있는지/사용 중인지를 비트 1개로 표시해서 빈 공간을 관리하는 방법입니다.
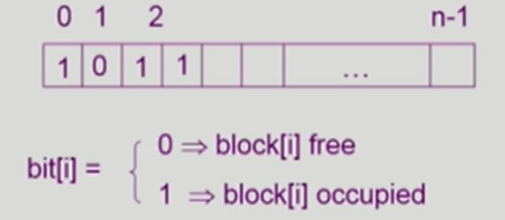
블록이 비어 있다면 0으로 설정하고, 블록이 사용 중이면 1로 설정합니다.
Bit map/Bit Vector는 구현이 단순하고 관리가 쉽고, 비트 단위라서 공간 효율이 좋습니다.
하지만 디스크가 커질수록 비트맵도 커져서 메모리 부담이 있습니다.
Linked List
Linked List는 빈 블록들만 골라서, 각 빈 블록이 ’다음 빈 블록’의 주소를 저장하도록 연결해 둔 방식입니다.
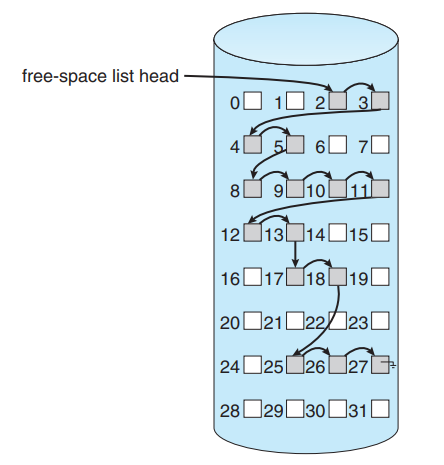
구현이 간단하고, 빈 공간 관리용 구조가 따로 크게 필요 없습니다. 하지만 리스트를 따라가며 확인해야 해서 ‘연속 공간 k개’ 같은 연속된 빈 블록 묶음 찾기가 어렵습니다.
Grouping
Grouping은 Linked List 방법의 변형으로, 빈 블록들을 연결 리스트로 관리하되 ’다음 빈 블록 1개’만 가리키는 대신 한 블록 안에 여러 개의 빈 블록 주소를 묶어서 저장하는 방법입니다.
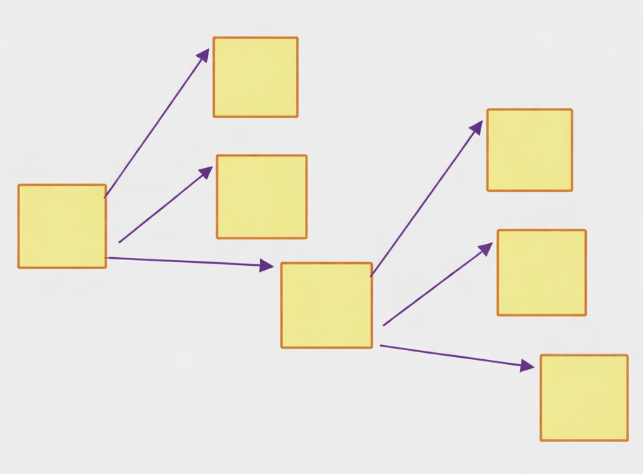
단순 linked list보다 다음 포인터를 얻기 위해 디스크에서 읽어야 하는 횟수가 줄어들기 때문에 디스크 I/O가 줄어들지만, 구현이 조금 더 복잡해집니다.
Counting
Counting은 연속된 빈 블록 구간을 한 덩어리로 보고, 각 덩어리를 (시작 블록 번호, 연속 개수)로 기록해서 빈 공간을 관리하는 방식입니다.
연속 빈 공간이 많을수록 표현이 매우 효율적이지만, 단편화가 있으면 구간(Counting)이 많아져서 오버헤드가 늘어납니다.
Directory Implementation
디렉터리는 파일 이름과 해당 파일의 메타데이터를 매핑하는 자료구조입니다. 파일을 열거나 생성할 때 디렉터리에서 이름을 검색하고, 생성/삭제 시 디렉터리 엔트리를 갱신합니다. 디렉터리에 파일 메타 데이터를 저장하는 방식으로 Linear List와 Hash Table이 있습니다.

Linear List는 디렉터리 엔트리들을 그냥 한 줄로 순서대로 저장하는 방식입니다. 구현이 간단하지만, 파일 수가 많아질수록 검색 비용이 증가합니다. →
Hash Table은 파일 이름을 해시 함수로 변환해서 나온 값(인덱스)에 따라 디렉터리 엔트리를 저장/찾는 방식입니다. 검색 성능이 좋지만, 해시 테이블 공간과 충돌(Collision) 처리 로직이 필요해 구현과 관리가 상대적으로 복잡합니다.
VFS(Virtual File System)과 NFS(Network File System)
운영체제는 다양한 로컬/원격 파일 시스템을 지원하기 위해 공통 인터페이스와 원격 접근 메커니즘을 제공합니다.
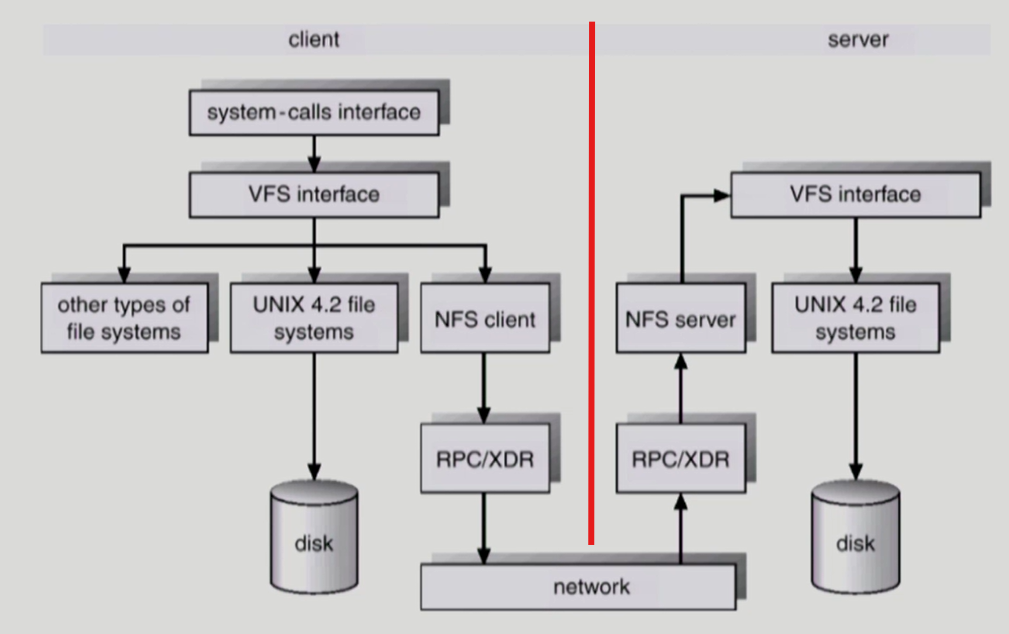
VFS는 커널 내부에서 파일 시스템을 추상화해 동일한 방식으로 접근하게 하고, NFS는 네트워크를 통해 원격 파일 시스템을 로컬처럼 사용하게 합니다.
Conclusion
이번 포스팅에서는 파일 시스템의 구현에 대해 자세히 알아봤습니다. 다음 포스팅에서는 디스크 관리 및 디스크 스케줄링에 대해 알아보겠습니다.
References
[2] Operating System Concepts(Silberschatz, Galvin and Gagne)