Fuzzing
Introduction to Fuzzing
오늘날 상용 프로그램의 코드는 수십만 줄을 넘고 매우 복잡하게 얽혀있어 사람이 직접 취약점을 찾는 것은 매우 어렵습니다. 또한 사람이 직접 만드는 테스트 케이스는 한계가 있고 24시간 내내 코드를 검토할 수 없습니다. 이러한 한계를 극복하고자 퍼징을 사용합니다.
Fuzzing
퍼징(Fuzzing)은 프로그램이나 시스템에 대량의 무작위 입력값을 주입하여 예기치 못한 동작을 유발함으로써 잠재된 버그나 취약점을 찾아내는 자동화 방법입니다. 퍼징을 사용하면 사람이 발견하기 어려운 엣지 케이스(Edge Case1)를 찾아낼 수 있고, 계속하여 코드를 검토할 수 있습니다.
이처럼 퍼징은 적은 시간 투자로 취약점을 탐지할 수 있지만, 많은 시간투자를 해야할 수 있는 방법론 중 하나입니다. 단순히 무작위 값만 넣어서는 높은 코드 커버리지(Code Coverage2)를 도달할 수 없기 때문에, 대상 프로그램의 구조를 이해하고 의미 있는 입력값을 생성하도록 퍼저를 설정해야합니다. 또한 퍼징이 찾아낼 수 있는 취약점의 종류에 한계가 있는데, 퍼징은 Memory Corruption 취약점 탐지에는 효과적이지만 Logic Bug 취약점 탐지에는 한계가 있습니다.
지금까지 살펴본 것처럼 퍼징은 사람이 놓치기 쉬운 엣지 케이스를 찾아낼 수 있고, 반복적으로 대규모 퍼즈 테스트를 수행함으로써 Memory Corruption 종류의 취약점을 효과적으로 발견할 수 있습니다. 이제부터는 이러한 퍼징의 기본 개념을 바탕으로, 일반적인 퍼징 알고리즘의 동작 과정을 단계별로 살펴보겠습니다.
Fuzzing Algorithm
일반적으로 퍼징 알고리즘은 전처리 과정과 Loop안의 Scheduling, InputGen, InputEval, ConfUpdate, Continue 과정으로 구성됩니다.
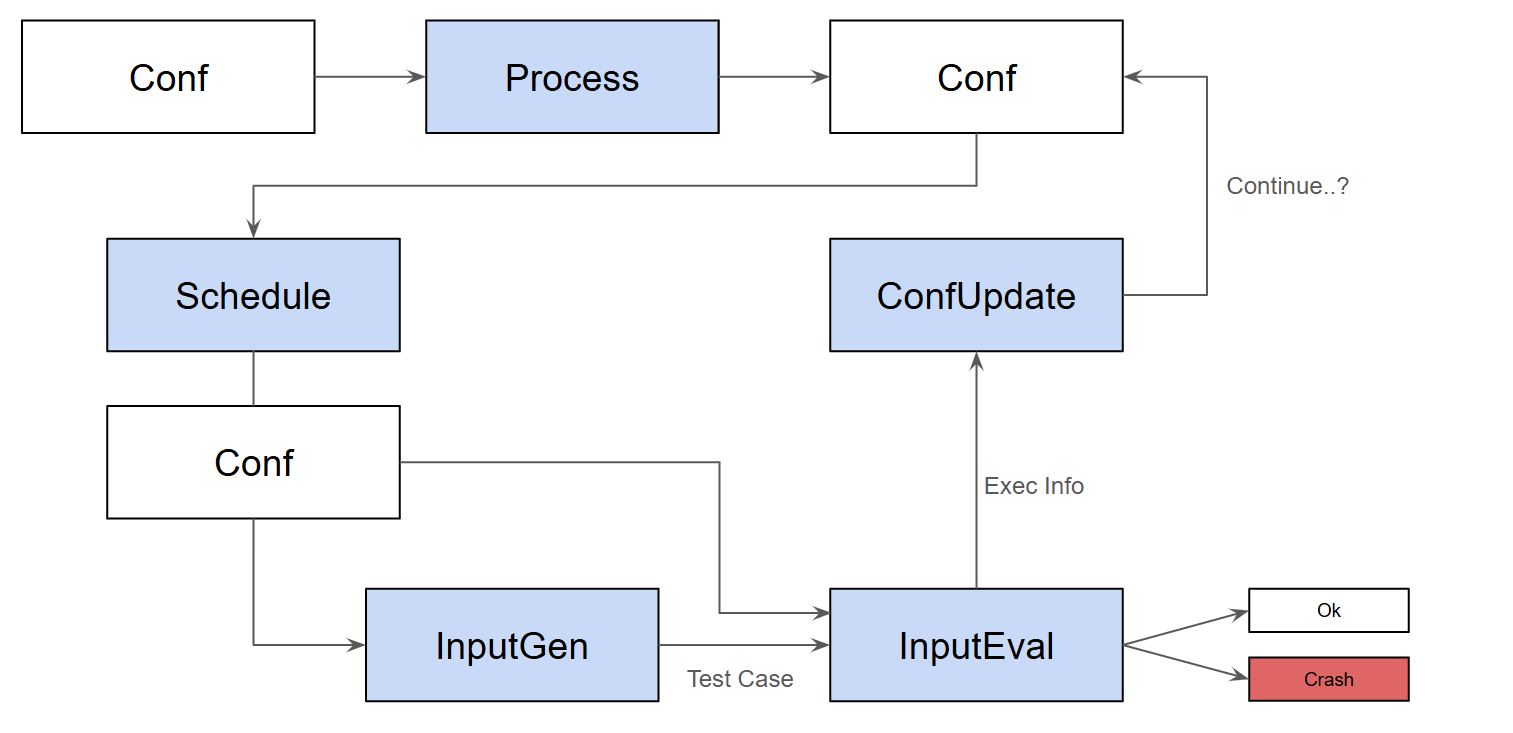
전처리 과정은 퍼징을 실행하기 전 타겟 프로그램에 계측(Instrumentation)코드를 삽입하고 시드(Seed)를 선정하는 등 퍼저 설정을 구성하는 단계입니다. 퍼저 설정이 완료되면 퍼저는 퍼징 설정을 기반으로 본격적인 Loop에 진입하여 다섯 가지 함수를 반복적으로 수행합니다.
스케줄링(Scheduling)은 퍼저가 어떤 시드를 선택해야 가장 좋은 결과로 이어질지 판단하고 해당 시드를 선택합니다.
그 다음, 선택된 시드를 기반으로 새로운 테스트 케이스를 생성하는 입력값 생성(InputGen)을 진행합니다. 이 단계는 생성된 입력값의 내용이 버그 트리거 여부를 직접 결정하기 때문에 퍼저 설계에서 매우 중요한 단계입니다. 입력 생성 방식은 크게 생성 기반과 변이(Mutation) 기반으로 나뉘는데, 입력 생성 방식은 타겟 프로그램의 입력 구조에 대한 사전 모델(Model)을 바탕으로 문법적으로 유효한 테스트 케이스를 처음부터 생성합니다. 변이 기반 방식은 기존에 수집된 입력값의 집합인 Corpus3를 기반으로 비트 플립, 바이트 삽입 및 삭제 등 다양한 변이 전략을 적용하여 새로운 테스트 케이스를 생성합니다.
입력값 평가(InputEval)에서는 생성된 테스트 케이스로 타겟 프로그램을 실행하며, 비정상적인 종료(Crash)가 발생하는지 감시하고 동시에 코드 커버리지와 같은 실행 정보를 수집합니다. 이후, 이 결과를 바탕으로 결과를 분석 및 처리(Triage) 과정을 거쳐 유의미한 결과만 선별합니다.
퍼저 설정 업데이트(ConfUpdate)단계는 입력값 평가 단계에서 얻은 실행 정보를 바탕으로 퍼저의 설정을 갱신하는 단계입니다. 특히, 새로운 코드 경로를 발견하는 등 ‘흥미로운’ 결과를 낸 테스트 케이스를 새로운 시드로 추가하여, 다음 퍼징 루프가 더 효율적으로 동작하도록 업데이트합니다.
Continue단계는 퍼저가 시작될 때 설정된 종료 조건을 만족했는지 확인하여 퍼징 루프를 계속 반복할지, 아니면 종료할지를 결정하는 마지막 단계입니다. 만약 조건을 만족했다면 퍼징 반복을 종료하고, 조건을 만족하지 못했다면 계속해서 퍼징을 수행합니다.
Fuzzing Categorization
지금까지 퍼징의 기본적인 동작 원리에 대해 알아보았습니다. 이제부터는 타겟 프로그램의 유형과 퍼저 구현 방식에 따른 퍼징 분류를 알아보겠습니다.
Type
먼저 타겟 프로그램의 유형에 따른 퍼징 분류에는 화이트박스, 그레이박스, 블랙박스 퍼징이 있습니다.
White Box Fuzzing
화이트박스 퍼징(White Box Fuzzing)은 대상 프로그램의 소스 코드나 내부 구조를 완전히 알고 있는 상태에서 퍼징을 수행하는 경우입니다. 가능한 실행 경로를 모두 탐색하여 다양한 경로에서 잠재적인 버그나 취약점을 발견하지만, 분기 수가 늘어날 수록 경로 폭발(Path Explosion) 문제가 발생할 수 있습니다.
Grey Box Fuzzing
그레이박스 퍼징(Grey Box Fuzzing)은 대상 프로그램의 일부 정보만을 사용하여 수행하는 퍼징입니다. 화이트박스 퍼징처럼 소스코드를 분석하고 경로 조건을 계산할 수 없지만, 런타임에 바이너리를 분석하여 커버리지를 수집해 퍼징을 수행합니다. 잘 알려진 AFL++, Libfuzzer가 Grey Box Fuzzing에 해당하며 필요에 따라 Harness4가 요구 됩니다.
Black Box Fuzzing
블랙박스 퍼징(Black Box Fuzzing)은 대상 프로그램의 내부 구조를 모르는 상태에서 퍼징을 수행하는 경우입니다. 활용 정보는 오직 출력값만 이용하며, Radamsa가 Black Box Fuzzing에 해당합니다.
Implementation
이제 퍼저 구현에 따른 퍼징 분류를 알아보겠습니다. 퍼저 구현에 따라 덤 퍼저, 스마트 퍼저가 있습니다.
Dumb Fuzzer
덤 퍼저(Dumb Fuzzer)는 입력 형식이나 대상 프로그램의 구조를 고려하지 않고 무작위 데이터 생성하여 삽입합니다. 내부 구조를 몰라도 빠르게 퍼즈 테스트를 수행할 수 있어 타겟 프로그램에 대한 사전 정보를 수집할 수 있습니다. 하지만, 유효한 입력을 만들 확률이 낮아 코드 커버리지가 대부분 낮습니다.
Smart Fuzzer
스마트 퍼저(Smart Fuzzer)는 프로그램에서 요구하는 입력 구조를 파악하여 유의미한 입력 값을 생성하고 삽입합니다. 높은 커버리지 달성을 통해 다양한 경로를 빠르게 탐색하고 유의미한 오류를 검출하는 데 유리합니다. 하지만 대규모 프로그램이나 다양한 문법이 존재하는 경우, 퍼저 구현 및 설정 단계의 난이도가 높아져 접근하기 어려울 수 있습니다.
Conclusion
이번 포스팅에서는 퍼징 방법론을 소개하기 위해 기본적인 개념, 일반적인 동작 원리와 퍼징 분류에 대해 살펴보았습니다. 만약 퍼징에 대해 관심이 생겨 논문을 보고 싶다면 다음 사이트를 참조하면 됩니다.
+2026.01.02 추가
많은 사람들에게 퍼징을 알려주다가 78리서치에서 좋은 블로그 글이 있어 추천하고자 추가 글을 작성하였습니다.
- Fuzzing: From Zero to 0-day #1 | Introduction to Fuzzing
- Fuzzing: From Zero 0-day #2 | Windows Application Fuzzing
References
[1] The Art, Science, and Engineering of Fuzzing A Survey