[OS-반효경] Process
Understanding Process
이번 포스팅에서는 프로세스에 대해 알아보겠습니다.
프로세스(Process)
프로세스(Process)는 실행중인 프로그램을 의미합니다. 디스크에 저장된 파일이 메모리에 적재될 때 프로세스가 됩니다. 프로세스에서 중요한 것은 문맥(Context)1인데, 프로세스 문맥을 나타내는 것은 다음과 같습니다.
- CPU 실행 상태를 나타내는 하드웨어 문맥 → PC(Program Counter), Registers
- 프로세스 주소 공간 → Code, Data, Stack
- 프로세스 관련 커널 자료구조 → PCB(Process Controll Block), Kernel Stack
프로세스 상태(Process State)
프로세스는 상태가 변경되며 실행이 됩니다.
Running: CPU를 점유하여 명령어(Instruction)를 실행하는 상태Ready: CPU를 기다리는 상태Waiting- CPU를 주어도 당장 명령어를 실행할 수 없는 상태
- Process 자신이 요청한 Event가 즉시 만족되지 않아 이를 기다리는 상태 ex) 디스크에서 파일을 읽어오는 경우
New: 프로세스가 생성 상태Terminated: 실행(Execution)이 끝난 상태
Note
Suspended(Stopped)은 외부적인 이유로 프로세스 실행이 중지된 상태입니다.
ex) 메모리에 너무 많은 프로그램이 적재되어 있어, 시스템이 프로세스를 중단시키는 경우
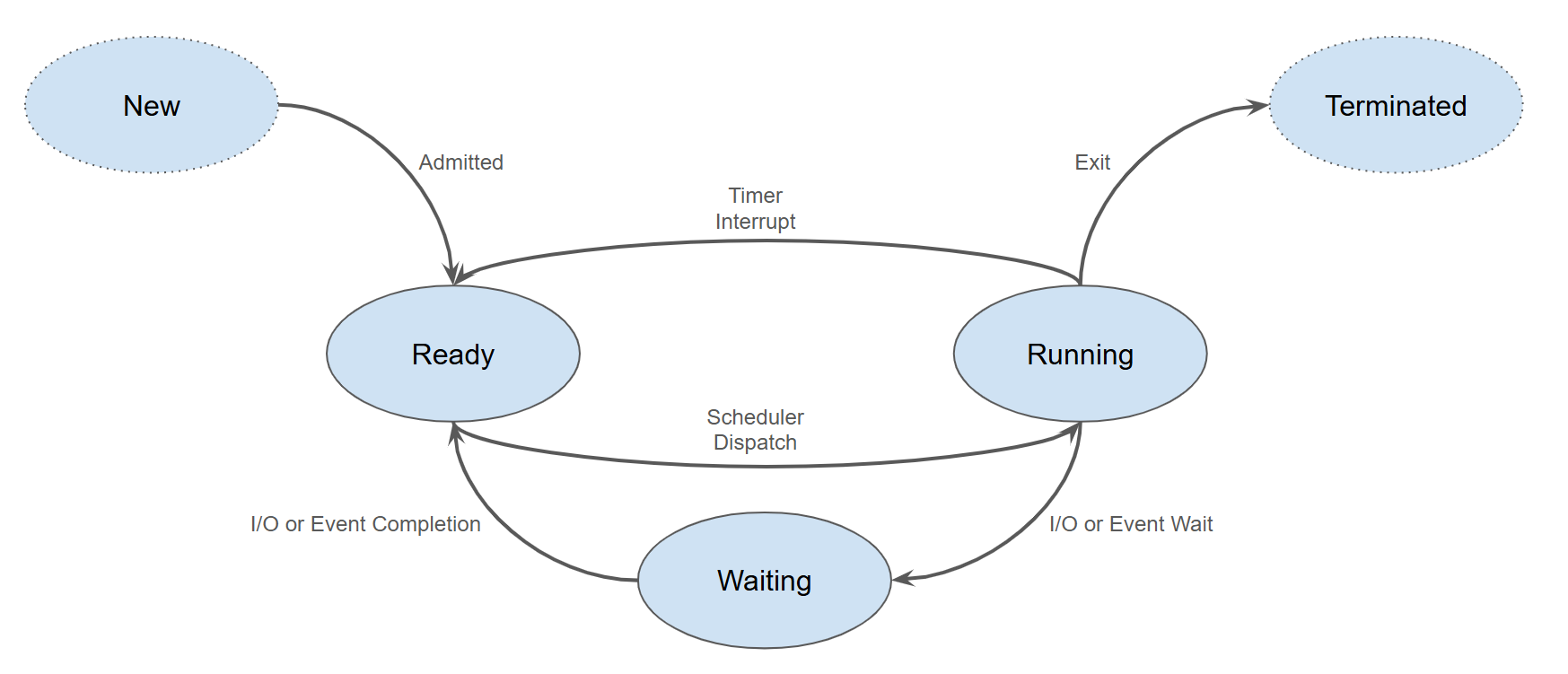
이제 프로세스 생성부터 종료단계를 알아보겠습니다. 사용자가 프로그램을 실행하면 운영체제는 프로세스를 생성(New)하고 필요한 여러 가지 자원을 할당합니다.
필요한 준비를 마치면 곧바로 다른 프로세스들이 대기하고 있는 준비(Ready) 상태로 이동합니다. 준비 상태는 CPU를 기다리는 상태로, 스케줄러가 준비 상태에 있는 프로세스 중 하나를 선택하여 CPU를 할당하면 프로세스는 실행(Running) 상태가 됩니다.2
실행 상태에 있다고 해서 계속해서 CPU를 점유할 수 없습니다. 할당된 시간이 끝나면3 다시 준비 상태가 됩니다. 또한, 시간이 오래 걸리는 작업(파일 입출력)이면 프로세스는 CPU를 다른 프로세스에게 넘겨주고 대기(Waiting) 상태가 됩니다.
그리고 요청한 작업이 끝나면4 다시 준비 상태로 돌아가 CPU를 기다립니다. CPU를 할당 받으면 다시 실행 상태가 되고, 만약 프로그램이 종료 된다면 프로세는 종료(Terminated) 상태가 됩니다. 종료된 프로세스의 자원 회수 및 PCB 정보가 없어지면 해당 프로세스는 소멸 됩니다. PCB와 관련된 내용은 다음과 같습니다.
PCB(Process Control Block)
PCB(Process Control Block)는 운영체제가 특정 프로세스를 관리하기 위해 각 프로세스 정보를 담고 있는 데이터 구조입니다. PCB의 요소에 대해 알아보겠습니다.
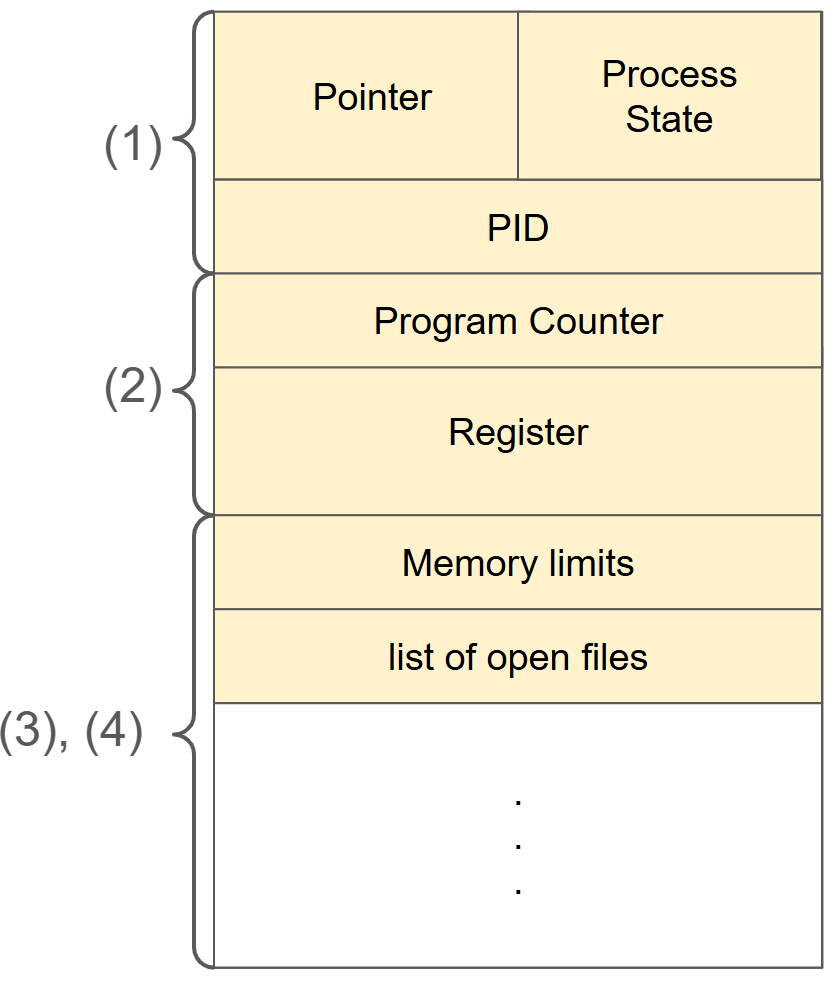
(1) 구역은 운영체제가 프로세스를 관리할 때 사용하는 정보입니다.
- 프로세스 상태, PID, Scheduling Information, Priority
(2) 구역은 CPU 실행 상태 관련 하드웨어 정보입니다.
- Program Counter, Registers
(3), (4)구역은 메모리와 파일 관련된 정보가 저장된 구역입니다.
- 메모리 관련 → Code, Data, Stack의 위치 정보
- 파일 관련 → Open File Descriptors
이처럼 PCB는 프로세스가 생성될 때마다 만들어지며, 운영체제는 이 PCB를 통해 프로세스의 정보를 파악하고 제어합니다.
Process Scheduling
이제 프로세스 스케줄링에 대해 알아보겠습니다. 프로세스 스케줄링(Process Scheduling)은 운영체제가 프로세스에게 자원을 할당하는 것을 의미합니다. 프로세스 스케줄러는 실행 주기에 따라 장기/단기/중기 스케줄러로 나뉩니다.
장기 스케줄러(Long-term Scheduler)는 프로세스에 메모리 및 자원을 주는 문제로, 시작 프로세스 중 어떤 프로세스를 Ready Queue로 보낼지 결정합니다. 이처럼 장기 스케줄러는 멀티프로그래밍 정도(Degree of Multiprogramming)를 제어합니다. 또한, 장기 스케줄러는 실행 빈도가 다른 스케줄러보다 낮으며, 장기 스케줄러를 Job Scheduler라고도 합니다.
단기 스케줄러(Short-term Scheduler)는 프로세스에 CPU를 주는 문제로, 어떤 프로세스를 실행 상태로 만들지 결정합니다. 단기 스케줄러는 다른 스케줄러보다 실행 빈도가 매우 높으며, 단기 스케줄러를 CPU Scheduler라고도 합니다.
시분할 시스템(Time Sharing System)는 보통 프로세스가 메모리에 바로 올라가기 때문에, 장기 스케줄러가 없습니다. 그래서 중기 스케줄러(Medium-term Scheduler)가 있고, 중기 스케줄러는 여유 공간을 마련하기 위해 프로세스에게서 메모리를 뺏어가는 문제입니다. 여유 공간을 마련하기 위해 프로세스 전부 메모리에서 디스크로 옮기는 Swap Out 동작을 하고, 장기 스케줄러와 똑같이 멀티프로그래밍 정도를 제어합니다. 또한, 중기 스케줄러를 Swapper라고도 부릅니다.
Process Scheduling Queues
프로세스 상태와 프로세스 스케줄링에서 언급한 것처럼, 프로세스는 각 큐를 오가며 실행됩니다. 아래는 프로세스 스케줄링 큐와 관련한 내용입니다.
- Job Queue: 현재 시스탬 내에 있는 모든 프로세스 집합
- Ready Queue: 현재 메모리 내 있으며, CPU를 할당을 기다리는 프로세스 집합
- Device Queue: I/O Device 처리를 기다리는 프로세스 집합
문맥 교환(Context Switch)
앞서 프로세스 상태가 변한다는 것과 프로세스 디스패치2에 대해 배웠습니다. 이처럼 한 프로세스에서 다른 프로세스로 CPU 제어권을 넘겨주는 것을 문맥 교환(Context Switch)이라 합니다.

위 사진을 기반으로 CPU 제어권을 내어주는 프로세스를 , CPU 제어권을 얻는 프로세스를 이라 하겠습니다.
- 문맥 저장: CPU를 사용하던 프로세스 가 실행을 멈추면, 운영체제는 의 상태를 의 에 저장합니다.
- 문맥 복원: 다음으로 CPU를 사용할 프로세스 의 에서 이전에 저장되어 있던 의 상태를 읽어와 CPU를 실행합니다.
이 과정을 통해 은 자신이 이전에 멈췄던 지점부터 다시 작업을 이어나갈 수 있습니다.
Thread
마지막으로 설명드릴 내용은 스레드입니다. 스레드(Thread)는 프로세스 내부에서 실행되는 최소 실행 단위입니다.
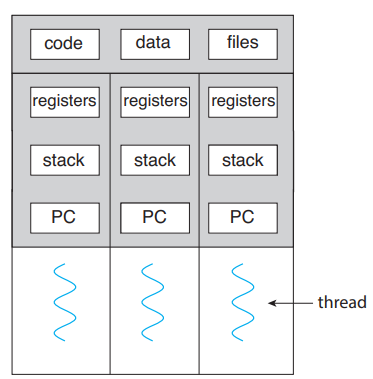
스레드는 Program Counter, Register Set, Stack, Code, Data, OS Resources 등으로 구성되어 있습니다. 스레드는 같은 프로세스에 속한 다른 스레드와 Code, Data, OS Resources 등을 공유하지만, Program Counter, Register Set, Stack는 공유하지 않습니다.
전통적인 프로세스는 하나의 스레드를 가지는 단일 스레드 형태지만, 최근의 프로세스는 한 프로세스에서 여러 스레드를 가지는 멀티 스레드로 구성되어 있습니다. 멀티 스레드는 하나의 스레드가 대기 상태인 동안에도, 동일한 작업 내의 다른 스레드가 실행되어 빠른 처리를 할 수 있습니다.
따라서 멀티 스레드를 사용하면 다음과 같은 장점이 있습니다.
- 응답성이 향상: 일부 스레드가 차단되거나 장시간 작업을 수행하더라도 다른 스레드는 계속해서 실행할 수 있습니다.
- 자원 공유성 → 자원을 효율적으로 사용할 수 있습니다. 즉, 프로세스 내의 스레드들은 메모리의 특정 영역(코드, 데이터, 힙 영역)을 공유하면서 복잡한 절차 없이 데이터를 공유합니다.
- 경제성: 새로운 프로세스를 만드는 것보다 새로운 스레드를 만드는 것이 훨씬 비용이 적게 듭니다.
- 확장성: CPU 코어가 여러 개일 때, 각 스레드를 서로 다른 코어에 할당하여 병렬로 작업을 처리할 수 있습니다.
또한, 멀티 스레드에서는 스레드를 관리하는 방식에 따라 커널 스레드와 유저 스레드로 나눌 수 있습니다. 커널 스레드(Kernel Thread)는 운영체제 커널에 의해 관리되는 스레드로, 커널이 각 스레드를 개별적인 실행 단위로 인식하고 직접 스케줄링합니다. 이렇게 커널 스레드는 커널이 각 스레드를 개별적으로 관리하고 스케줄링할 수 있어, 멀티코어 시스템에서 병렬처리를 할 수 있습니다. 하지만 스레드 생성 및 전환 시 커널 모드로 전환이 필요하므로 유저 스레드보다 오버헤드가 높고 관리하기가 복잡합니다.
유저 스레드(User Thread)는 커널이 해당 스레드를 인지하지 못한채, 사용자 프로그램 라이브러리 지원을 받아 관리되는 스레드입니다. 커널의 개입 없이 라이브러리가 직접 스레드를 전환하므로 매우 빠르지만, 커널이 스레드를 모르기 때문에 구현에 제약이 있을 수 있고 하나의 스레드가 막히면 해당 프로세스가 멈추는 단점이 있습니다.
Conclusion
이렇게 이번 포스팅에서는 프로세스 정의, 상태, 스케줄링, 스레드 등 프로세스와 관련된 전반적인 내용에 대해 알아보았습니다. 다음 포스팅에서는 프로세스의 생성 및 종료에 대해 알아보고 그와 관련된 시스템 콜 등을 알아보겠습니다.
References
[2] Operating System Concepts(Silberschatz, Galvin and Gagne)