[OS-반효경] Process Synchronization(Concurrency control)
Race Condition, Critical Section, Atomic Instruction, Semaphore, Monitor..🤐
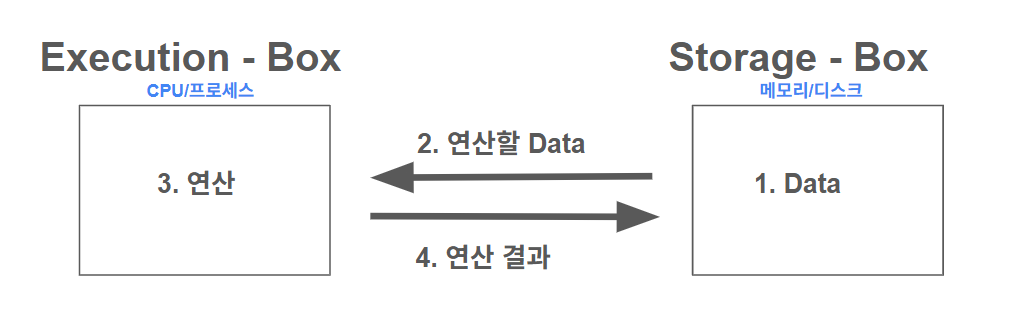
컴퓨터에서 데이터에 접근(연산)은 실행 주체(E-box)와 데이터 저장 공간(S-box)의 상호작용으로 이루어집니다.
하나의 프로세스가 데이터에 접근할 때는 아무런 문제가 없지만, 여러 실행 주체가 하나의 공유 자원(S-box)에 동시에 접근할 때 Race Condition이나 데이터 불일치가 나타날 수 있습니다.
따라서 운영체제는 이러한 문제를 막고 데이터의 일관성을 유지하기 위해 프로세스 간의 실행 순서를 조율하는 메커니즘이 필수적입니다. 이번 포스팅에서는 이와 같은 프로세스 동기화 문제를 살펴보겠습니다.
Race Condition
Race Condition은 여러 실행 주체가 같은 공유 자원을 동시에 다룰 때, 순서 및 타이밍에 따라 결과가 달라지는 문제입니다. 운영체제에서 Race Condition은 다음과 같은 상황에서 발생할 수 있습니다.
- Kerenl 수행 중 인터럽트 발생 시
- Process가 System Call을 하여 Kernel mode로 수행 중인데 Context Switch가 일어난 경우
- Multiprocessor에서 Shared Memory 내의 Kernel Data에 접근할 때
먼저 커널 수행 중 인터럽트가 발생한다면 Race Condition이 발생할 수 있습니다.
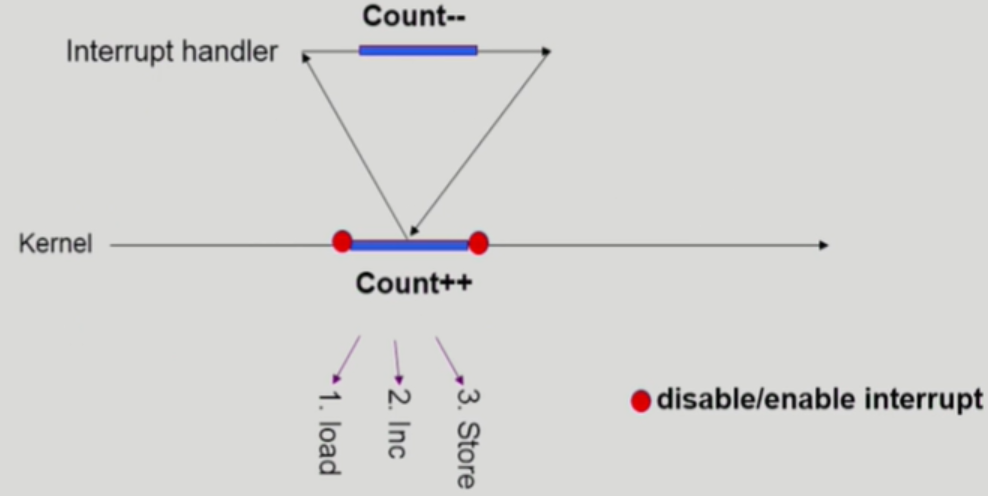
고급 언어에서 count++와 같은 증가 연산은 한 줄의 코드지만, 실제 기계어에서는 load, inc, store 명령어로 나뉘어 독립적으로 실행됩니다.
문제는 이 3단계 과정이 atomic1하지 않기 때문에, 명령어가 실행되는 도중 다른 명령어로 인터럽트가 발생하면 결과가 적용이 안될 수 있습니다.
예를 들어 커널이 count++를 수행하기 위해 load → inc → store 순서로 명령어를 실행한다고 해보겠습니다.
그런데 load로 count 값을 레지스터에 올린 직후 인터럽트가 발생하고, 인터럽트 핸들러가 count--를 수행한 뒤 복귀하면, 해당 감소 연산이 count 변수에 반영이 안됩니다.
커널은 인터럽트 동안 count 값이 변경됐다는 사실을 알 수 없어서, 레지스터에 남아 있던 값에 inc를 적용한 뒤 그대로 store하기 때문입니다.
이처럼 커널 수행 중 인터럽트가 발생하면 Race Condition이 발생할 수 있기 때문에, 공유 데이터를 갱신하는 구간에서는 인터럽트를 잠시 disable하여 해당 코드가 끊기지 않도록 보장하면 됩니다.
프로세스가 시스템 콜을 하여 커널 모드로 수행 중인데 문맥 교환이 일어난 경우에도 Race Condition이 발생할 수 있습니다.
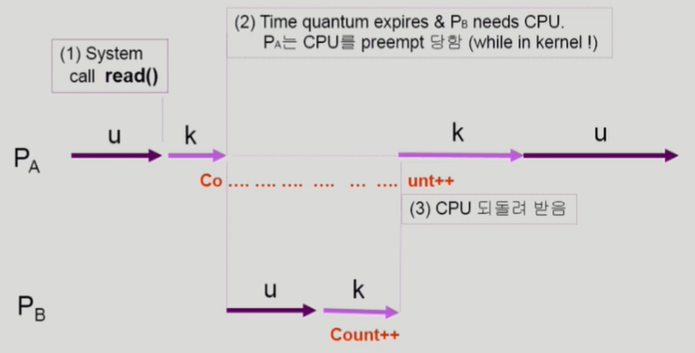
위 사진이 직관적이고 이전 Race Condition이 나타나는 경우와 거의 비슷한 내용이라서 추가적인 설명은 생략하겠습니다. 커널 모드에서 CPU를 preempt하지 않고, 유저 모드로 돌아 왔을 때 preempt하면 됩니다.
마지막으로 멀티 프로세서에서 공유 메모리 내 커널 데이터에 접근한다면 Race Condition이 발생할 수 있습니다.
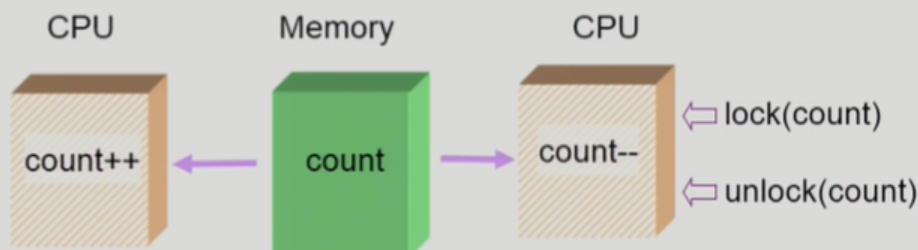
단일 CPU에서는 커널이 공유 데이터를 갱신하는 동안 인터럽트를 잠시 disable하면 Race Condition을 방지할 수 있습니다. 하지만 멀티프로세서는 한 CPU에서 인터럽트를 disable해도 다른 CPU는 계속 커널 데이터에 접근할 수 있기 때문에 Race Condition이 발생할 수 있습니다.
이를 해결하는 방법은 커널 데이터에 한 번에 하나의 CPU만 접근할 수 있도록 제한하는 것입니다.
또 다른 방법은 공유 커널 데이터에 접근할 때마다 lock을 걸고 작업이 끝나면 unlock을 해, 동시에 접근하지 못하도록 막는 것입니다.
결국 Race Condition을 막으려면, 공유 자원을 접근/갱신하는 코드 구간을 ‘동시에 실행되지 않게’ 만들어야 합니다. 운영체제에서는 이 구간을 Critical Section2이라고합니다.
The Critical Section Problem
Critical Section 문제는 여러 실행 주체가 공유 자원에 동시에 접근하지 않도록, 한 번에 하나만 진입하게 보장하는 동기화 문제입니다.
Critical Section 문제를 해결하기 위해 Mutual Exclusion, Progress, Bounded Waiting을 모두 만족해야 합니다.
Mutual Exclusion: 한 시점에 Critical Section에는 하나의 실행 주체만 들어갈 수 있어야 함Progress: Critical Section에 들어갈 프로세스를 고르는 결정이 무한히 미뤄지면 안됨Bounded Waiting: 어떤 프로세스가 Critical Section에 들어가고 싶어서 요청을 했으면, 그 이후로는 언젠가 반드시 들어갈 수 있어야 함
Initial Attempts to Solve Problem
Critical Section 문제를 해결하려고 시도한 방법은 다음과 같습니다.
do { entry section critical section exit section remainder section} while (1);critical section과 아닌 영역으로 구분하고, 동기화를 위해 동기화 변수를 설정합니다.
Critical Section에 접근하기 전 동기화 변수를 확인하여 Critical Section에 진입 여부를 결정하고, Critical Section에 진입한 이후에 동기화 변수를 해제하는 방식으로 동기화 문제를 해결하려고 했습니다.
좀 더 구체적인 설명은 다음과 같습니다.
Algorithm 1
int turn;initially turn = 0;동기화 변수(turn)는 자신의 차례라는 것을 알려주는 변수입니다.
do { while (turn != 0); /* My turn? */ critical section turn = 1; /* Now it's your turn */ remainder section} while (1);이처럼 자신의 차례가 되면 critical section에 접근하고, 접근 이후에는 동기화 변수를 해제하여 동기화를 진행합니다.
이 방식은 서로 반드시 교대로 들어가야만 했기 때문에 Critical Section에 자주 접근해야하는 프로세스가 있다면 비효율적입니다.
Algorithm 2
boolean flag[2];initially flag[모두] = false; /* no one is in CS */프로세스마다 동기화 변수(flag)를 설정하여 critical section에 들어가고 싶다면 true로 값을 변경했습니다.
do { flag[i] = true; /* Pretend I am in */ while (flag[j]); /* Is he also in? then wait */ critical section flag[i] = false; /* I am out now */ remainder section} while (1);이 방법은 Mutual Exclusion을 만족하지만, 프로세스들이 모두 flag를 설정한다면 Progress와 Bounded Waiting을 만족하지 못합니다.
그래서 프로세스들이 while (flag[j]);에서 끊임없이 양보하는 상황이 발생할 수 있습니다.
Algorithm 3(Peterson’s Algorithm)
do { flag[i] = true; turn = j; /* Set to his turn */ while (flag[j] && turn == j); /* wait only if.. */ critical section flag[i] = false; remainder section} while (1);이는 Algorithm 1과 Algorithm 2를 결합한 방법입니다.
만약 서로 다른 프로세스들이 critical section에 접근하고 싶을 때, 우선권(turn = j)이 있다면 우선권이 있는 프로세스가 먼저 진입합니다.
그 이후, 우선권이 있는 프로세스가 critical section에서 나왔다면 critical section에 접근하는 알고리즘 입니다.
Mutual Exclusion, Progress, Bounded Waiting을 모두 만족한 알고리즘이지만, while (flag[j] && turn == j);조건이 풀릴 때까지 while에서 계속 조건을 확인하므로 CPU를 계속 소모합니다.
이를 Busy Waiting이라 하며 Spin lock이라고도 합니다.
Synchronization Hardware
지금까지는 소프트웨어적으로 Critical Section 문제를 해결하는 방법에 대해 알아보았습니다. 하드웨어적으로 Critical Section 문제를 해결하는 방법은 아키텍처에서 atomic 명령어를 제공하면 해결할 수 있습니다.
Semaphore
세마포어는 위에 나온 알고리즘과 atomic 명령어를 추상화 한 개념입니다.
즉, 세마포어는 여러 프로세스가 공유 자원에 동시에 접근하는 것을 제어하기 위해 사용되는 프로세스 동기화 메커니즘으로 P와 V연산이 있습니다.
while (S ≤ 0) do no-op;S--;P연산은 자원을 획득하는 연산으로 lock을 생각하면 됩니다.
S++;V연산은 자원을 반납하는 연산으로 unlock을 생각하면 됩니다.
do { P(mutex); critical section V(mutex); remainder section} while (1);이는 기본적인 세마포어를 활용한 코드입니다.
피터슨 알고리즘은 while (...)로 조건을 계속 확인해야 하므로 Critical Section에 들어가지 못한 프로세스가 CPU를 점유한 채로 대기하는 Busy Waiting이 발생했습니다.
하지만 세마포어는 자원이 없을 때 프로세스를 Block하고, 자원이 반환되면 프로세스를 Wakeup하는 Block/Wakeup 방식을 구현할 수 있습니다.
Block/Wakeup Implementation
typedef { int value; /* semaphore */ struct process *L; /* process wait queue */} semaphore- 세마포어 정의
S.value--; /* prepare to enter */if (S.value < 0) /* Oops, negative, I cannot enter */{ add this process to S.L; block();}- P연산 정의
S.value++;if (S.value <= 0) { remove a process P from S.L; wakeup(P);}- V연산 정의
이렇게 세마포어를 Block/Wakeup 방식으로 구현할 수 있습니다. Block/Wakeup 방식은 CPU 낭비를 줄일 수 있지만, 대신 Block/Wakeup 과정에서 오버헤드가 발생합니다.
따라서 Busy Waiting 방식과 Block/Wakeup 방식은 상황에 따라 적절한 선택이 달라지며, 어떤 경우에 어떤 방식이 더 유리한지 비교해볼 필요가 있습니다.
Critical Section의 길이가 긴 경우 Block/Wakeup 방식이 유리합니다. Critical Section의 길이가 짧으면 Block/Wakeup 오버헤드가 Busy waiting 오버헤드 보다 보통 더 크기 때문입니다.
Deadlock, Starvation
세마포어는 Critical Section 문제를 해결하지만, Deadlock과 Starvation 문제가 발생할 수 있습니다.
Deadlock은 둘 이상의 프로세스가 서로가 가진 자원을 기다리며, 모두가 영원히 진행하지 못하는 상태입니다.
예를 들어 프로세스 A가 S1을 획득한 뒤 S2를 기다리고, 동시에 프로세스 B가 S2를 획득한 뒤 S1을 기다리면 두 프로세스 모두 block된 채로 멈추게 됩니다.
Starvation은 특정 프로세스가 계속 우선순위에서 밀리거나 자원을 얻지 못해, 무한히 대기하는 상태입니다.
Race Condition에서 매번 다른 프로세스가 먼저 P(mutex)에 성공해 임계 구역에 들어가면, 어떤 프로세스는 계속 기다리기만 하고 실행 기회를 얻지 못할 수 있습니다.
더 자세한 내용은 다음 포스팅에서 다루기 때문에 짧게 설명하고 넘어가겠습니다.
동기화와 관련된 전통적인 문제 3가지
동기화와 관련된 전통적인 문제가 3개 있습니다.
- Bounded-Buffer Problem(Producer-Consumer Problem)
- Readers and Writers Problem
- Dining-Philosophers Problem
해당 문제들은 예전부터 많은 사람들이 다뤄왔고 좋은 자료들이 많기 때문에 본 포스팅 글에서는 소개만 하고 설명은 넘어가겠습니다. 각 문제 상황에 대한 자료를 링크를 함께 걸어놓았기 때문에 참고하시면 됩니다.
Monitor
세마포어는 강력한 동기화 도구이지만, P와 V를 호출하는 순서가 조금만 꼬여도 Deadlock이나 Starvation 같은 문제가 쉽게 발생할 수 있습니다.
또한 공유 자원을 보호하기 위한 코드가 여기저기 흩어지기 때문에, 프로그램이 커질수록 동기화 로직을 올바르게 유지하기가 어렵습니다.
이러한 문제를 해결하기 위해 등장한 개념이 Monitor입니다.
Monitor는 공유 자원과 그 자원을 접근하는 연산들을 하나의 모듈로 묶고, Critical Section 진입을 언어/런타임 수준에서 관리해 동기화를 더 안전하게 제공합니다.
즉, 프로그래머가 lock/unlock을 직접 맞춰주기보다, Monitor 내부에서 자동으로 Mutual Exclusion을 보장하고 필요한 경우에만 조건에 따라 Block/Wakeup을 수행합니다.
Conclusion
이번 포스팅에서는 프로세스 동기화 문제에 대해 다뤄 봤습니다. Race Condition, Critical Section, Atomic Instruction, Semaphore, Monitor 등 많이 낯설고 어려운 개념들이 나왔지만 제대로 이해하고 넘어가는 것을 권장합니다. 다음 포스팅에서는 Deadlock에 대해 알아보겠습니다.
References
[2] Operating System Concepts(Silberschatz, Galvin and Gagne)
[3] Classical Problems of Synchronization with Semaphore Solution